如何让 Django API 再快一点 (2)
0X00 前言
啊,这个破系统怎么这么慢。 -你写的程序的用户
是的我写过一篇类似的博客,但是一篇肯定说不完,毕竟影响性能的东西太多了:数据量巨大、机器配置差、查询SQL效率低、额外的多余的查询、低质量的代码balabala的。今天这篇文章主要是从Django查询和ORM层面来分析一下API变慢的原因。
其中可能性比较多,我这里先挑几个我经常遇到的情况来说:不管自己的需求直接查询所有字段、完全不在意索引、疯狂使用in、循环创建/更新数据、不善于使用缓存。这几个问题其实都会对我们的API响应速度造成比较大的影响,下面我们来一个个介绍一下。
0X01 SELECT *
首先我们一定知道,从数据库里查询的数据越多那反应也就越慢。我这里拿一个只有500条数据的表来展示一下,这里可以看到两次的耗时虽然都很短(那可不嘛,就500条数据),但是比例上还是差了三倍还多,如果随着数据量变大和字段变多这个差距就会更加明显。但是我们可以看到在循环里只需要name这个字段,多余的是用不到的。
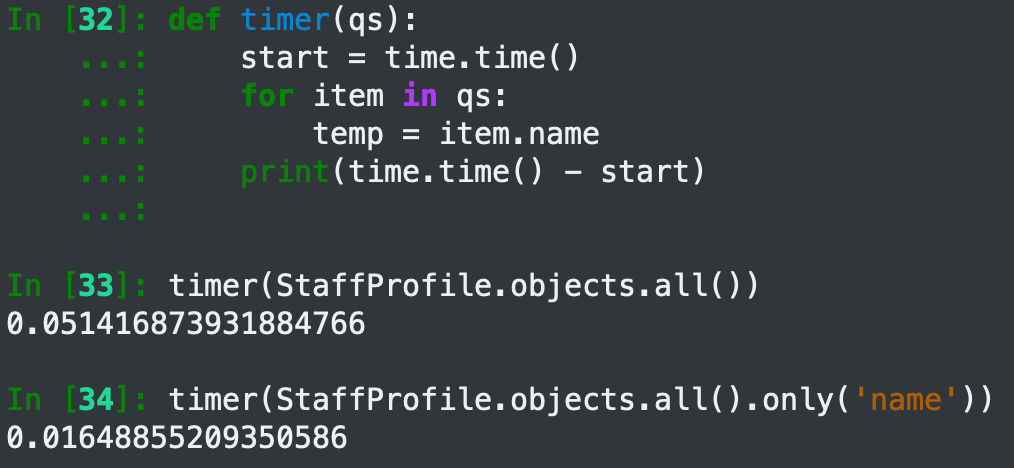
实际上这两个查询执行的是不同的两个SQL(当然了这是废话),那具体区别呢?可以看到一个是SELECT * 一个是单独取了两个字段。
1 | SELECT * FROM `main_staffprofile`; -- 其实并不是一个*,而是把所有字段都列在这儿了,这里方便展示就不都贴出来了 |
所以说,当我们确定知道自己下面要用到什么字段的时候,就给queryset加上only('xxx', 'xxx', 'xxx')的参数,从数据库里取的时候尽可能少的取数据,这样就能加快查询了。尤其是在查得的数据很大和字段很多的时候,比如在表里取10000条数据但是只用到30列中的3列的时候就非常应该加上only。
0X02 Index/index_together
好吧,说起优化速度就绕不开索引,这是必然的。我们都知道在数据库里给字段加索引可以大幅提升查询效率,具体在Django里建立普通索引也是很简单的,直接在字段定义里加一个参数index=True就好了。但是可能大家会忽视联合索引的建立,这里简单介绍一下:
1 | class Meta: |
Django中的每个Model类我们都会创建一个Meta子类,子类里有一个属性叫做index_together顾名思义这就是定义联合索引的地方了。index_together是一个二维数组,第一维度下面的每个item都是一个联合索引,第二个维度下面的每个item就是一个字段,也就是构成联合索引的字段(注意联合索引是讲究顺序的喔)。具体索引和联合索引应该怎么建才会让数据查询更快可以看我上一片博客或者搜索其他资料。
注意:索引/联合索引定义好之后需要进行数据库迁移
0X03 IN balabala
我们在Django的查询中无处不见这种User.objects.filter(user_type__in=('1', '2', '3', '4,', '5'))的用法,这种用法在业务上确实有需求,所以我们是避免不掉的。不过还是可以通过一些其他的方法来尝试规避,比如从业务上看看这些选项组合到一起的时候是不是意味着一种特殊的数据,比如User.objects.filter(city__in=('成都', '绵阳', '自贡'........))可以发现是在查询四川省,那么可以考虑换成User.objects.filter(province='四川'')这种。或者User.objects.filter(level__in=('A', 'B', 'C', 'D', 'E', 'F'))是不是意味着User.objects.exclude(level='S')。
这种情况因为业务上的严格需求,可能并没有太好的调节方法(也可能是我没想到,如果大家有方法的话欢迎反馈给我,谢谢指教🙏),不过遇到了的话还是可以尝试上面两种方案,玩意能行的话还是可以调节一下性能的。
0X04 疯狂关联
条条大路通罗马。
疯狂关联也比较容易出现,正所谓条条大路通罗马,但是总会有一条更近一点的路。比如这种User.objects.filter(father__father__name='shawn'')完全就可以用User.objects.filter(grandfather__name='shawn'')这种来替代。这个其实大家都会比较清楚,对技术没什么考验,但是比较考验对程序的理解程度尤其是数据库的理解程度。有时候我们接手一个新的项目时候可能并没有对这个项目的数据库有充分的了解,所以可以尝试在写这种多层的关联查询之前取调研一下是不是有更近的通向罗马的路。
0X05 bulk_create
这种问题应该是最常遇到的了。我们从前端接收到了这么一波数据要写到数据库里(数据哪儿来的并不重要,也可能是csv来的或者其他什么鬼地方)
1 | [{'name': 'shawn_0'}, |
新手同学很有可能写出如下代码:
1 | for user in user_list: |
但是我们来看看速度,耗时4秒,再看一下批量创建的时间,耗时0.13秒,性能提升了很多倍。

批量创建虽好,但是有一点就需要特别注意:如果你要创建的数据比较复杂并且量非常大,请不要一次性全部创建完成,否则可能会对数据库造成较大的压力,可以尝试将比如10000条数据分成10个1000或者100个100来创建。
0X06 cache/cached_property
缓存可能是提升性能最明显的方案了,同样数据量的数据从MySQL里取出来和从Redis里取出来,耗时根本不在一个数量级,所以我们应该善用缓存。
比如我们有一个巨大的关键词配置放在数据库里存起来了,大概有10W条数据,平时又很少更新,但是经常会查,那就非常适合使用缓存。我们可以这样
1 | def get_keyword_config(): |
然后在更新关键词库的时候再同时刷新一次缓存就好了。另一种使用缓存的方式是Django中带的cached_property。我们知道Django中有一个property可以把function作为属性来用,直接通过点就能获取值,这个顾名思义就是加了缓存的property。也就是说每次调用student_count的时候都要计算一遍,但是调用cached_student_count的时候只有第一次会计算,后面就是缓存的值了。
1 | class Teacher(models.Model): |
下面是官方文档关于cached_property的解释,简单明了: 注意里面提到的生命周期,小心用到已经失效的数据
将一个类方法转换为特征属性,一次性计算该特征属性的值,然后将其缓存为实例生命周期内的普通属性。 类似于 property() 但增加了缓存功能。 对于在其他情况下实际不可变的高计算资源消耗的实例特征属性来说该函数非常有用。
1 | class DataSet: |