写给新手的 Iptables 使用说明
0X00 基础知识
常用 Linux 的各位估计都知道 iptables、firewalld 和 ufw 这三个工具吧,或者还知道 netfilter 这个内核组件。但是他们究竟是什么关系呢?从关系上来讲,可以将他们分成三层:最底层是 Linux 的安全框架 netfilter,上面是用来操作 netfilter 的 iptables,再上层是 firewalld 和 ufw。
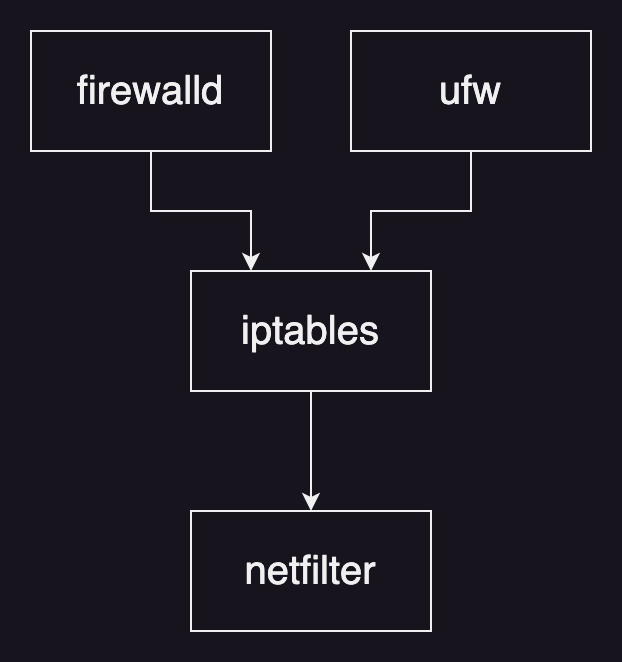
其中 firewalld 一般会默认安装在 RHEL 和 CentOS 中,ufw 会默认安装在 Debian 和 Ubuntu 中。不过由于很多人还是习惯直接操作 iptables 所以这次的重点就是它了。很多人会说 iptables 是防火墙,这其实并不严谨,它的标准定义应该叫做 Packet Filter 也就是包过滤工具。而且事实上也是如此,它不仅能够实现防火墙的限制流量功能,还能提供 NAT 转发的能力。
iptables 内部总共拥有 4 张表(table),又有多个链(chain),如下图所示。
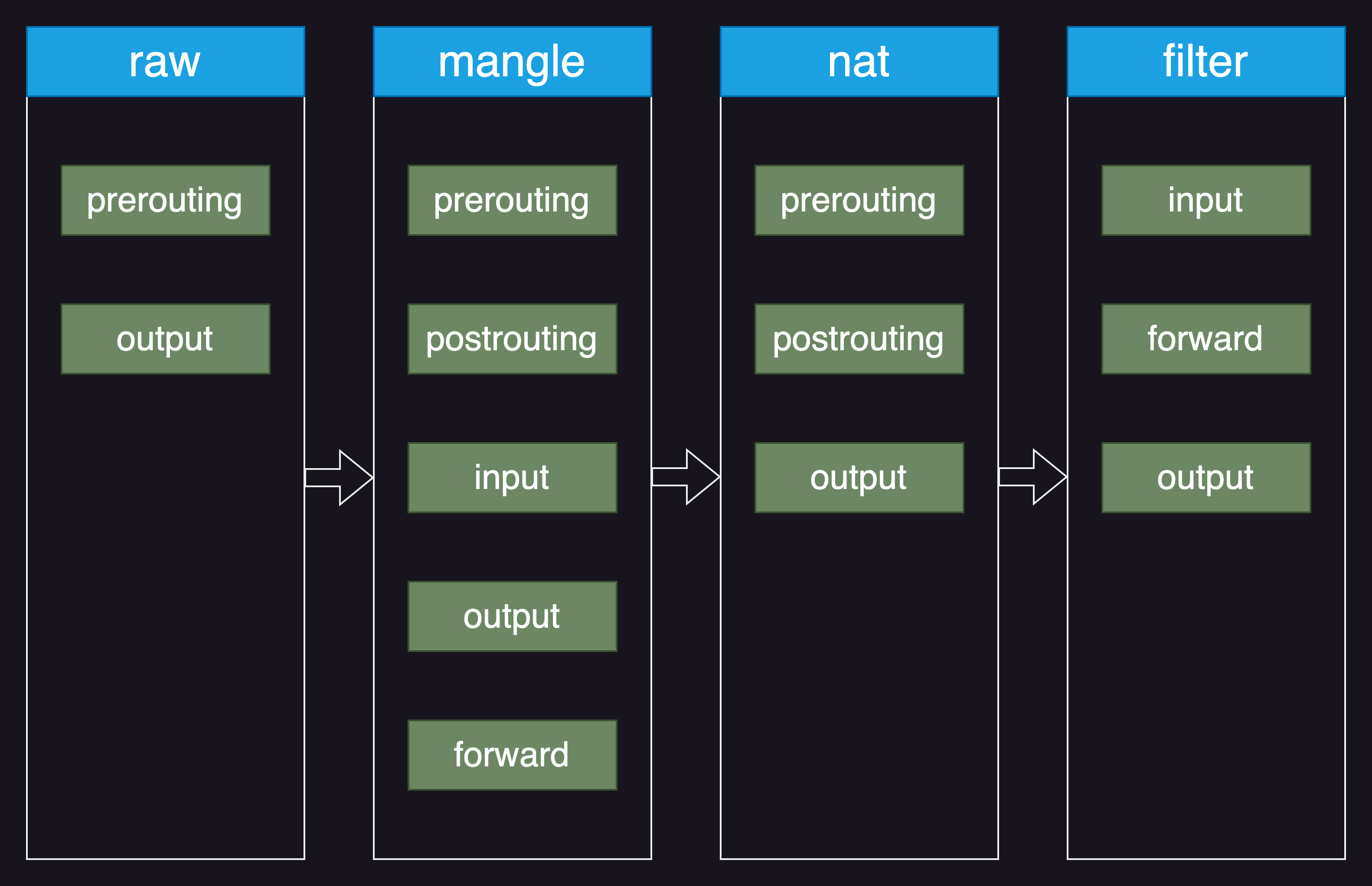
既然是「写给新手的 iptables 使用说明」,自然是挑选最重要的一部分来介绍的,也就是 nat 和 filter 两张表。其中 filter 表应该是我们接触最多的表,它用于决定一个数据包的「命运」,比如你想将某些数据包拦截在外,或者堵住前往某地址的出口就可以用它实现。在使用 iptables 命令时不手动指定表的话就是在操作 filter 表。另一个 nat 表顾名思义就是用来配置 NAT(网络地址转换)的了。
需要注意,严格来说本次只说明
iptables和与之强相关的命令,也就是说只涉及 IPV4 的配置。如果需要配置 IPV6 的规则,则需要使用ip6tables命令,虽说两个命令大差不差,但是这里还是以 IPV4 为主,也只考虑纯 IPV4 环境。
在开始使用命令之前,先要给出一张图作为前置知识:注意看这张图(略复杂,不过前期看不明白也不影响基本的使用)。可以看到其实流量不是从一个表一个表走下去的,而是按照链的顺序在前进,并且不同的流量会走的路径也不完全一致。
另外再给出一些常用的命令,用来辅助后面的实验。
1 | 查看 filter 表的所有规则(因为没指定表,所以是默认的 filter 表) |
实验环境:
毕竟实践出真知,建议搞一台最好两台在同一网段的虚拟机进行试验。
注意,接下来两个章节的的命令都是临时生效的,所以如果玩砸了可以直接 iptables -t nat/filter -F 清空规则,或者重启虚拟机从头来过。具体如何将规则写入配置中使其持久化,可以查看章节 0X03 的内容。
0X01 filter 表
既然 filter 表是最常见的,那就从它开始吧~ filter 表中有 input/forward/output 这三个 chain,顾名思义就是分别用来控制传入流量、数据包转发、传出流量的。如果你想控制哪些流量能来不能来,就去在 input 链上加规则;想做流量转发就去在 forward 链上加规则;想控制出口流量就去在 output 链上加规则。
放行 22 端口
我自己比较喜欢对着完整命令拆解其参数来学习它的用法,所以也就这样演示了,所以先来看命令吧。
1 | iptables -A INPUT -i eth0 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT |
先看第一条命令,我们把它拆成几个部分来看
iptables就不用多说了,就是这个工具本身;-A INPUT其中-A参数是 append 的意思,就是在 INPUT 链上追加规则;-i eth0其中-i是 in-interface 的意思,就是指定了从 eth0 来的流量(要注意来字,是有方向的);-p tcp很好理解,-p就是 protocol,指定了 tcp 协议;--dport 22其中的-dport是 destination port 的缩写,也就是指定了目的端口是 22;-m state指的是匹配类型选择了「状态匹配」,与后面的--state配合使用;--state NEW,ESTABLISHED是与上面的-m state配合的参数,指的是匹配新建的连接和已经存在的连接;-j ACCEPT其中-j指的是跳转(jump)到具体操作,这里指的是 ACCEPT,也就是放行;
所以第一句用人话来说就是:在 filter 表的 INPUT 链上新增一条规则,放行来自 eth0 且访问本地 22 端口的 tcp 流量(包括新建的和已经存在的连接)。看似很长,其实拆解完之后就简单很多了,而且很多时候我们并不需要在命令中加入 -m state --state NEW,ESTABLISHED 的参数。
在第一个命令的基础上看第二行的命令就更简单了,只是将 INPUT 链换成了 OUTPUT 链,并且是将 --dport 改成了表示 source port 的 --sport。这样一来这句话的含义就是:在 filter 表个 OUTPUT 链上新增一条规则,放行从 eth0 的 22 端口出去的 tcp 流量。注意这里的 -o eth0 指的是从 eth0 口出去的流量,与上面的 -i eth0 形成了对比,这里的 -o 是 out-interface 的意思。
检查配好的规则
我们执行完这两条命令之后查看一下 iptables -L -n 的输出,我这里是这样的
1 | Chain INPUT (policy ACCEPT) |
这里解释一下
-n参数,默认情况下 iptables 会去尝试解析规则中出现的 ip 对应的 hostname 和 port 对应的 servicename,我们为了更加直观的看到刚刚的结果(速度也会更快),就添加了-n的参数。它的作用就是让 iptables 不去解析 hostname 和 servicename,直接以数字化的形式(Numbric)展示出来。
从输出中已经可以看到我们配置上去的这两条规则了。另外可能还注意到了 Chain INPUT (policy ACCEPT) 的这块,它的意思是说 INPUT 链的默认规则就是 ACCEPT,也就是说默认情况下所有的入站流量都是会被放行的,OUTPUT 链也是一样,这里就该介绍一下默认情况了。
默认规则
可以使用 iptables -P INPUT DROP 命令来将入站流量的默认值设为 DROP 也就是抛弃(当然也可以将其改为 ACCEPT 了),这里的 -P 参数意思是 Policy。
iptables 中的默认值意思是当一个数据包没有命中配置的任何一条规则时,采用的策略,也就是一个兜底的选择。所以说如果你对服务器的安全性要求比较高,就可以将其出入站的默认值都设置为 DROP,然后再根据需求开放指定的 ip、port、protocol 等。
特定来源/目的地以及端口
下面再看两个命令
1 | iptables -A INPUT -s 192.168.81.0/24 -p tcp --dport 2333 -j DROP |
这里直接看这个新参数 -s 和 -d 吧,他们分别表示 source 和 destination,也就是来源和目的地。后面跟的不仅可以是一个标准的 ip 地址,也可以是 CIDR 的一段 IP 地址。通过上面两个命令,就拒绝了来自 192.168.81.0/24 且访问自己 2333 端口的 tcp 请求,也拒绝了访问 192.168.81.0/24 的 2333 的 tcp 请求。
我们已经知道 -p 参数接受的是协议名称,这里再强调一下它只能接受「网络层协议」,比如你写一个 -p http 或者 -p arp 是不行的。他只能接受:tcp/udp/udplite/icmp/icmpv6/esp/ah/stcp/mh 这些参数,或者用 all 表示所有(其实不加 -p 参数就是指代所有)。
防止被 ping
比如你想禁止别人 ping 自己,就可以用这样的一个命令来阻止:(ping 命令使用的是 ICMP 协议)
1 | iptables -A INPUT -p icmp -j DROP |
关于 forward
只有当你的机器作为路由器工作的时候 forward 链才有配置的必要,绝大多数情况下是并不需要配置 forward 的。介于这篇博客是写给新手的,这里就不涉及路由器的配置了。
0X02 nat 表
了解的人肯定了解 nat 是个什么东西,不过比起 filter 这个非常直观的名字来说还是需要简单介绍一下:
网络地址转换(英语:Network Address Translation,缩写:NAT),又称IP动态伪装(英语:IP Masquerade),是一种在IP封包通过路由器或防火墙时重写来源或目的IP地址或端口的技术。这种技术普遍应用于有多台主机,但只通过一个公有IP地址访问网际网路的私有网络中。 – wikipedia
一般来说操作 nat 表除了要做 SNAT(源地址转换) 和 DNAT(目的地址转换)之外,就是搞端口转发了,且真正去做 NAT 的需求又并不常见,所以针对 nat 表我们就只介绍有关转发的内容好了。
确认允许转发
有些发型版本默认是不允许转发的,我们可以通过 cat /proc/sys/net/ipv4/ip_forward 检查当前是否允许 ip 转发。很明显,如果输出的是 1 就是允许,0 就是不允许了。修改它也很简单,直接把 0 或者 1 重定向写入进去就好了,比如 echo 1 > /proc/sys/net/ipv4/ip_forward。
细心的你可能发现了,这个文件路径它包含 ipv4 这个字段,那它是不是只能修改 IPV4 的转发呢?确实。如果需要修改 IPV6 的转发则需要改动 /proc/sys/net/ipv6/conf/ens33/forwarding 这个文件。并且注意这个文件中的 ens33,它表示具体某个网口,需要按需修改。如果你想修改所有的网口,可以将它修改为 all。
细心的你可能还发现了,这个文件路径它在 /proc 下面,貌似并不能持久化?确实。如果需要将转发的配置持久化的话需要修改 /etc/sysctl.conf 文件,找到对应的配置修改为下面的配置,再使用 sysctl -p 将其应用就可以了。
1 | net.ipv4.ip_forward = 1 |
下面的例子都是在开放了转发之后进行的。
端口转发
在我的另一篇博客里提到了使用 ssh 命令建立隧道的方式实现转发,这里再利用 iptables 搞一下。假设你现在有 3 台机器,如下图:B 有两张网卡,接入两个子网,与 A 和 C 均相通,但由于 A 和 C 并不在同一子网内,所以两者无法沟通。现在你想让 A 顺利访问 C 部署在 2333 端口的服务应该怎么办呢?
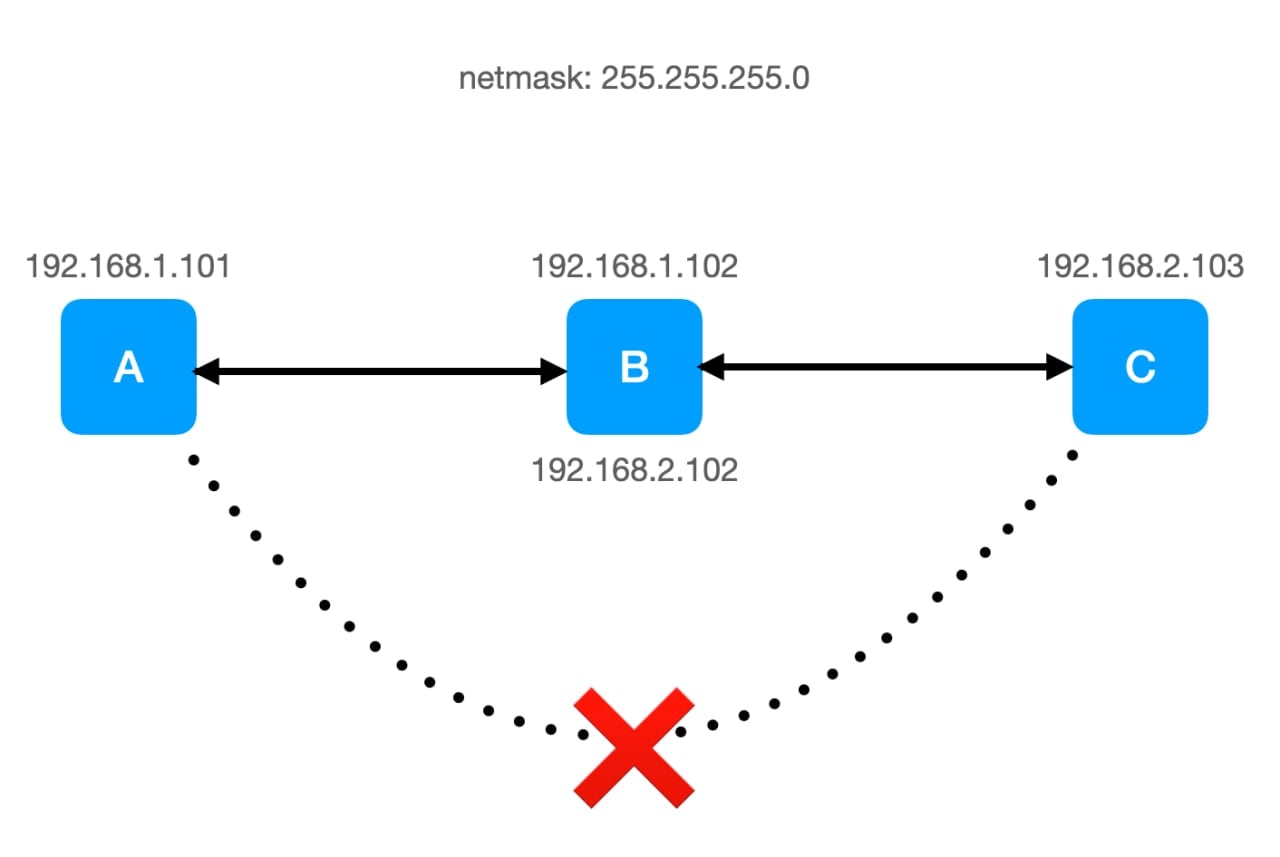
从原理上说,既然 A 能访问 B,B 能访问 C,那只要你让 B 在其中负责转发(传话)就没有问题了。
所以我们进行如下配置:
1 | sudo iptables -t nat -A PREROUTING -p tcp --dport 2333 -j DNAT --to-destination 192.168.2.103:2333 |
先来看第一行配置:
-t nat是指定了操作 nat 表;-A PREROUTING是指定了在 PREROUTING 链中追加规则;-p tcp --dport 2333是指定了目的端口为 2333 的 tcp 流量;-j DNAT是指定了跳转到 DNAT(目标地址转换)操作;--to-destination 192.168.2.103:2333则是将目的地设置为 ip:port;
再来看第二行配置:
-A POSTROUTING是指在 POSTROUTING 链中追加规则(跟第一行不一样哈);-j MASQUERADE实现伪装,也就是说将自己转发出去的数据包伪装成本就是自己发的;
这样一来本来不通的 A 和 C 就通过 B 这个传话员成功通信了。
如果你发现你配置好了之后并不能成功通信,需要检查 B 节点是否允许转发(上面说了怎么设置)。确认允许转发还不行的话,再检查自己 filter 表的 forward 链是否会允许你的这个数据包通过。检查就很简单,直接用
iptables -L就可以,正常来说它输出的内容你一定能看懂。
0X03 配置文件与持久化
开头的时候说过,这些命令的改动都是临时的,那么如何让它持久化呢?一般有这两种方法:iptables-save + iptables-restore 或者单用 iptables-persistent。两种方法不分优劣,硬要说的话后一种方法比较「优雅」,但是大多数人还是用的前一种方法,所以建议跟他人协作的工作中还是使用第一种方法(除非你有办法说服别人用第二种)。
save + restore
iptables-save 和 iptables-restore 这两个命令是跟随 iptables 一起的,不用担心没有安装的问题。前者的功能就是输出当前 iptables 的配置(与 iptables 一般命令不同,这个命令默认就是所有 table 了),后者就是恢复 iptables 配置。
我们可以使用 iptables-save > iptables_config 来把当前生效的规则导出成文本文件,重启之后想要恢复之前的配置用 iptables-restore < iptables_config 就可以了。不过按照习惯,大家会把这个配置文件放在 /etc/iptables/rules.v4 里(看名字也知道,IPV6 的配置一般文件名是 rules.v6)。
接下来只需要写一个脚本让系统启动的时候自动导入这个配置就可以了。这里建议将脚本命名为 /etc/network/if-pre-up.d/iptablesload,因为 /etc/network/if-pre-up.d/ 目录是一个比较特别的目录。看名字也能猜到,在网口被 up 之前会查找这个目录下的可执行文件,逐个执行一遍,这样一来就可以做到当网口 up 起来的时候 iptables 已经处于配置好的状态了。最后记得给脚本一个可执行权限,就 ok 了。
1 | !/bin/sh |
如果是使用的是 Debian 系的操作系统直接按上述操作就行,如果是 RHEL 系的话可能需要配置 systemd 的服务才行。或者使用下面这种更加优雅的方法~
iptables-persistent
这种方法看起来优雅很多,不过 iptables-persistent 并不会随 iptables 一起安装,所以需要额外安装一下。安装过程中它就会两次询问你 Save current IPv4/6 rules?,如果你回答了 Yes 那么当前系统中已经配置好的规则就会通通写入到 /etc/iptables/ 中,并且命名为 rules.v4 和 rules.v6(没错,就是上面一种方式里提到的位置)。
每次你手动改完了规则之后就可以使用 netfilter-persistent save 将规则写入到配置文件中,如果你把规则搞乱了也可以使用 netfilter-persistent reload 将配置文件重新套用。
0X04 其他
删除规则
我们一直在说创建规则,那怎么删除规则呢?其实很简单,例如你用 iptables -A INPUT -p tcp --dport 2333 -j DROP 命令创建的入站规则,其中 -A 指的是追加一个规则,那你把它就它换成 -D 就是 Delete 了。所以用上面这个命令创建的规则可以用 iptables -D INPUT -p tcp --dport 2333 -j DROP 删除掉。
规则的匹配顺序
需要注意的一点是,规则匹配是按照顺序自上而下的,这里看一个 iptables -L 的输出:
1 | Chain INPUT (policy ACCEPT) |
我们可以看到 INPUT 链上有两条针对 2333 端口的入站规则,第一条 DROP,第二条 ACCEPT。两条规则会按照顺序执行,所以说当遇到第一条 DROP 的时候连接就被 DROP 了,第二条的 ACCEPT 则永远走不到。
插入规则
看了上面两个,你可能会想:既然 -A 是 append,且匹配有顺序,那肯定支持一个 -I 的 Insert 操作。确实!
我们首先看这个命令 iptables -L --line-numbers 的输出:
1 | Chain INPUT (policy ACCEPT) |
可以看到我配置了 4 条规则,分别是禁止 2333/2334/2335/2336 的 TCP 入站。现在我想允许这个 123.123.123.123 地址访问我的 2333 端口该怎么搞?最简单的就是在最前面插入一个规则。具体可以用这下面这条命令来在位置 1 的地方 Insert 一条规则(并且把其他规则挤下去)。
1 | iptables -I INPUT 1 -s 123.123.123.123 -p tcp --dport 2333 -j ACCEPT |
再来看一下现在的配置,发现新规则已经被放在最前面了:
1 | Chain INPUT (policy ACCEPT) |
修改规则
修改一条规则与插入规则没什么区别,只是将 -I 参数换成了 -R Replace 参数而已,后面的都完全一致。